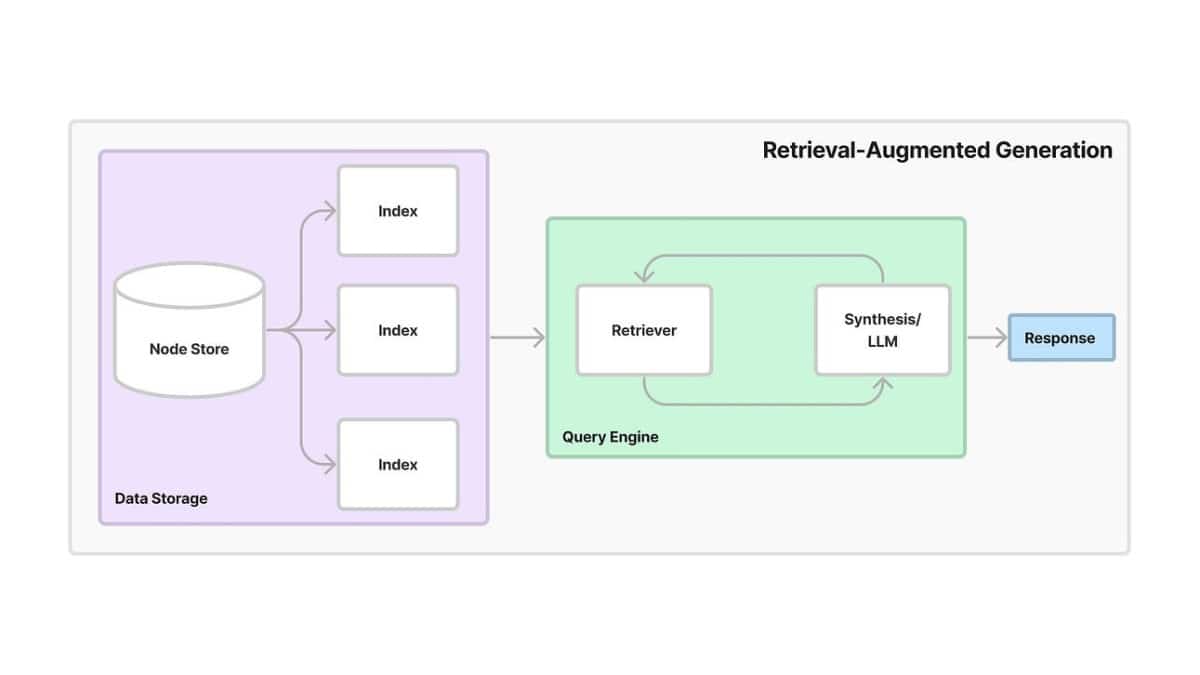
Le Retrieval Augmented Generation (RAG) est une technologie révolutionnaire qui combine les capacités de grands modèles de langage (LLM) avec des techniques avancées de recherche d’informations. Cette approche vise à améliorer la précision et la pertinence des réponses générées par les LLM en intégrant des sources de données externes.
Dans cet article, nous explorerons en détail le fonctionnement du RAG, les algorithmes sous-jacents, les étapes clés du processus, et les avantages et inconvénients de cette technologie innovante.
Les algorithmes derrière le retrieval augmented generation
Le RAG repose sur deux composantes principales : la récupération d’informations et la génération de texte. Les algorithmes utilisés pour ces deux composantes sont cruciaux pour assurer la performance du système.
Récupération d’informations
Les algorithmes de récupération d’informations sont conçus pour identifier les passages les plus pertinents à partir d’une vaste base de données. Ces algorithmes utilisent des techniques d’indexation et de recherche pour faciliter l’identification rapide des informations pertinentes. Parmi les algorithmes couramment utilisés, on trouve BM25, TF-IDF, et des modèles de langage pré-entraînés comme BERT (Bidirectional Encoder Representations from Transformers) qui excelle dans les tâches de compréhension de texte.
Génération de texte
Une fois les informations pertinentes récupérées, elles sont utilisées par le modèle de génération de texte. Les LLM, tels que GPT (Generative Pre-trained Transformer), sont optimisés pour utiliser le contexte fourni par les données récupérées et générer des réponses cohérentes et informées. Ces modèles sont entraînés sur d’énormes quantités de données textuelles, ce qui leur permet de produire des réponses de haute qualité.
Les étapes clés du processus de retrieval augmented generation
Le processus de RAG peut être divisé en trois étapes clés : la préparation des données, la récupération des informations, et la génération de texte.
Préparation des données
La première étape consiste à structurer et indexer les données externes (documents, articles, bases de données, etc.) pour faciliter leur recherche et leur récupération. Un modèle de recherche est mis en place pour identifier les informations pertinentes en fonction des requêtes soumises.
Récupération des informations
Lorsqu’une requête est soumise, le modèle de recherche identifie les passages les plus pertinents dans les données externes. Ces passages sont extraits et fournis au LLM en tant que contexte supplémentaire. Cela permet au modèle de disposer d’informations à jour et spécifiques pour générer des réponses plus précises.
Génération de texte
Le LLM utilise la requête initiale et le contexte récupéré pour générer une réponse. En s’appuyant sur des informations pertinentes et à jour, le LLM peut produire des réponses plus précises, informées et complètes.
Comparaison entre retrieval augmented generation et les modèles traditionnels
Le RAG offre plusieurs avantages par rapport aux modèles de langage traditionnels, qui s’appuient uniquement sur les données internes pour générer des réponses.
Précision et pertinence
Les modèles traditionnels peuvent souffrir de limitations en termes de précision et de pertinence, car ils ne disposent pas d’accès à des informations externes. Le RAG, en revanche, utilise des sources de données externes pour améliorer la qualité des réponses, réduisant ainsi les risques d’hallucinations (invention de faits par le modèle).
Adaptation à des domaines spécifiques
Le RAG permet d’adapter facilement les LLM à des domaines spécifiques en utilisant des sources de données pertinentes. Cela est particulièrement utile pour des applications nécessitant des connaissances spécialisées, telles que la médecine ou le droit.
Actualisation des connaissances
Les LLM traditionnels peuvent devenir obsolètes s’ils ne sont pas régulièrement réentraînés avec de nouvelles données. Le RAG permet aux modèles d’accéder à des informations à jour grâce à la récupération de données en temps réel.
Avantages et inconvénients du retrieval augmented generation
Avantages
- Réduction des hallucinations : En fournissant des preuves tangibles, le RAG réduit considérablement le risque d’hallucinations.
- Amélioration de la factualité : Les réponses générées sont plus susceptibles d’être factuelles et fiables, car elles sont basées sur des sources d’information vérifiées.
- Adaptation à des domaines spécifiques : Le RAG permet d’adapter facilement les LLM à des domaines spécifiques en utilisant des sources de données pertinentes.
- Actualisation des connaissances : Les LLM peuvent accéder à des informations à jour grâce à la récupération de données en temps réel.
Inconvénients
- Complexité : La mise en œuvre du RAG est plus complexe que celle des modèles traditionnels, nécessitant une infrastructure pour la récupération et l’indexation des données.
- Dépendance aux données externes : La qualité des réponses dépend de la qualité et de la disponibilité des données externes utilisées.
Utilisation de bases de données dans le retrieval augmented generation
Les bases de données jouent un rôle crucial dans le RAG, fournissant les informations externes nécessaires pour améliorer la précision des réponses générées par les LLM. Ces bases de données peuvent inclure des documents, des articles de recherche, des encyclopédies, et même des bases de données spécifiques à des industries particulières.
Le rôle de l’apprentissage supervisé dans le retrieval augmented generation
L’apprentissage supervisé est utilisé pour entraîner les modèles de récupération d’informations et de génération de texte. Ces modèles sont optimisés en utilisant des ensembles de données annotés, où les passages pertinents et les réponses appropriées sont marqués. Cela permet aux modèles d’apprendre à identifier les informations pertinentes et à générer des réponses cohérentes et précises.
Optimisation des performances dans le retrieval augmented generation
Pour optimiser les performances du RAG, plusieurs techniques peuvent être employées, telles que l’amélioration des algorithmes de recherche, l’augmentation des données d’entraînement, et l’optimisation des architectures de modèles. En outre, l’intégration de feedback utilisateur et de mécanismes d’évaluation continue permet de maintenir et d’améliorer la qualité des réponses générées.
Les outils courants pour le retrieval augmented generation
Plusieurs outils et frameworks sont disponibles pour mettre en œuvre le RAG, notamment :
- Hugging Face Transformers : Une bibliothèque populaire pour les modèles de langage et de récupération d’informations.
- Elasticsearch : Un moteur de recherche puissant utilisé pour indexer et rechercher des données textuelles.
- Faiss : Un outil de Facebook AI Research pour la recherche de similarité de vecteurs à grande échelle.
Exemples de projets utilisant le retrieval augmented generation
De nombreux projets et entreprises utilisent le RAG pour améliorer leurs services. Par exemple :
- Moteurs de recherche : Des entreprises comme Google et Bing utilisent des techniques de RAG pour fournir des réponses plus précises et contextuelles aux requêtes des utilisateurs.
- Chatbots et assistants virtuels : Des assistants virtuels comme Siri et Alexa utilisent le RAG pour améliorer la qualité des conversations et fournir des informations fiables.
- Rédaction de contenu : Des plateformes de rédaction automatisée utilisent le RAG pour aider les rédacteurs à trouver des sources d’inspiration et à produire du contenu informatif.
N’hésitez pas à partager vos expériences et opinions sur le RAG dans les commentaires ci-dessous !
FAQ sur le retrieval augmented generation
Qu’est-ce que le retrieval augmented generation (RAG) ?
Le Retrieval Augmented Generation (RAG) est une technique qui combine les capacités des grands modèles de langage (LLM) avec des techniques de récupération d’informations pour améliorer la précision et la pertinence des réponses générées.
Quels sont les avantages du RAG par rapport aux modèles traditionnels ?
Le RAG réduit les hallucinations, améliore la factualité des réponses, permet une adaptation facile à des domaines spécifiques, et offre des informations à jour grâce à la récupération de données en temps réel.
Quels sont les outils courants utilisés pour le RAG ?
Les outils couramment utilisés pour le RAG incluent Hugging Face Transformers, Elasticsearch, et Faiss, qui facilitent la mise en œuvre des modèles de langage et des techniques de récupération d’informations.
Partagez votre avis dans les commentaires et engagez la discussion sur ce sujet fascinant !